Neues im kommenden PostgreSQL 9.3

Datenbank-Tuning

Mit der Version 9.3 liefert die PostgreSQL-Community wieder etliche wichtige, neue Features in einer Hauptversion. Sie ist das Werk vieler Entwickler weltweit und durchlief einen strengen Review-Prozess (Commitfest), der die Qualität des Quelltextes sicherstellt. In der Regel finden sich bis zu 100 Patches in diesen Commitfests – wegen der Menge muss besonders vor dem Feature Freeze einer neuen Hauptversion die dafür veranschlagte Zeit regelmäßig verlängert werden. Die Liste an hinzugekommenen Funktionen ist entsprechend beeindruckend. Dieser Artikel stellt die Wichtigsten vor.
Parallel Dump
Ein lange von den Anwendern (aber auch von Entwicklern) gefordertes Feature ist die Möglichkeit, Dumps einer Datenbank mit mehreren Threads oder Prozessen gleichzeitig auszuführen. PostgreSQL verwendet eine Multiprozessarchitektur, das heißt, es benutzt keine Threads (auch nicht auf Plattformen wie Windows, die sie eigentlich favorisieren). Um mit
»pg_dump«
parallel mehrere Objekte zu sichern, muss das Programm deshalb mehrere Datenbankverbindungen öffnen. Da jedoch
»pg_dump«
die Konsistenz eines Dumps auch mit nebenläufigen Transaktionen garantiert, müssen diese zu
»pg_dump«
gehörenden Datenbankverbindungen nun synchronisiert werden. Aus diesem Grund gestaltete sich die Entwicklung dieses Features recht langwierig.
Snapshot Cloning
Die Infrastruktur, die hierfür implementiert wurde, nennt sich Snapshot Cloning. Dieses Verfahren gestattet es, mehrere Transaktionen derart untereinander zu synchronisieren, dass sie denselben Zustand sehen, obwohl es sich doch um separate Datenbankverbindungen handelt. Grundsätzlich muss zuerst eine Transaktion gestartet werden, die dann synchronisiert werden kann. Alle weiteren Transaktionen importieren dann den dabei erzeugten Snapshot. Dies synchronisiert dann die jeweilige Transaktion mit ihrer "Elterntransaktion", beide haben dann dieselbe Sicht auf den Zustand der Datenbank.
Abbildung 1
verdeutlicht den Ablauf. Zunächst wird eine Transaktion gestartet. Diese muss den Isolationsgrad
»REPEATABLE READ«
oder
»SERIALIZABLE«
haben.
»READ COMMITTED«
ist nicht möglich, da sich innerhalb dieses Isolationsgrades der Snapshot nach jedem Kommando ändert und nicht dauerhaft für die Transaktion ist.
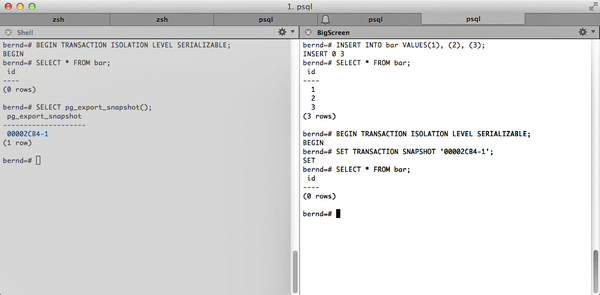 Abbildung 1: Die zweite Transaktion rechts bezieht sich auf einen zuvor angelegten Snapshot: So sieht sie dieselben Daten.
Abbildung 1: Die zweite Transaktion rechts bezieht sich auf einen zuvor angelegten Snapshot: So sieht sie dieselben Daten.
Mit der Funktion
»pg_export_snapshot()«
kann in jeder beliebigen Transaktion ein Snapshot exportiert werden. Die Rückgabe ist ein Datum vom Typ TEXT mit dem Bezeichner des Snapshots. Dieser Bezeichner kann in einer anderen Transaktion mit dem Kommnado
»SET TRANSACTION SNAPSHOT«
importiert werden.
Zu beachten ist, dass dies das erste Kommando innerhalb der Transaktion oder vor jedem anderen
»SELECT«
,
»INSERT«
,
»UPDATE«
oder
»DELETE«
sein muss. Ferner kann eine importierende Transaktion mit
»SERIALIZABLE«
-Isolationsgrad keinen Snapshot einer Transaktion importieren, deren Isolationsgrad kleiner ist.
Ähnliche Artikel
-
PostgreSQL 10

-
Hochverfügbarkeit und Replikation für PostgreSQL

-
PostgreSQL 10 Beta veröffentlicht
Die nächste Generation der PostgreSQL-Datenbank bringt zahlreiche Verbesserungen mit.
-
Überblick zu PostgreSQL 14.4

- Asynchrone Replikation in PostgreSQL 9
Konfigurationsmanagement

Themen


