
ZFS-Architektur
Die oberste Ebene bildet die Schnittstelle zum Userland und anderen Diensten, welche die Daten im Netzwerk bereitstellen. Dieser Layer wird Interface Layer genannt. Dies ist auf der einen Seite ein Posix-Layer, um Netzwerkdateisysteme wie NFS über die entsprechenden Daemons an ZFS anzubinden. Auf der anderen Seite dient der ZFS-Volume-Emulator dazu, eine Schnittstelle für andere lokale Dateisysteme wie beispielsweise UFS2, Auslagerungsdateien oder iSCSI zu bieten. Auch Jails kommunizieren über diese Ebene mit ZFS. Die nächste Schicht ist der Transactional Object Layer, gewissermaßen das Herz von ZFS. Hier findet die Verwaltung der Snapshots, Transaktionen und Datenverwaltung statt.
Die unterste Ebene ist der sogenannte Storage-Pool-Manager. Besonders hervorzuheben ist der ZFS-Intent-Log (ZIL), die Cache-Verwaltung mit dem Adaptive Replace Cache (ARC) und dem Second Level Adaptive Replace Cache (L2ARC). Während ZIL Schreibvorgänge in einem Journal protokolliert, verhält sich der ARC/L2ARC wie ein zweistufiger Read-Cache, wobei der ARC sich im Arbeitsspeicher und der L2ARC auf einer Festplatte (oder SSD) befindet.
Volume-Manager
Herkömmliche Dateisysteme verwalten in der Regel nur eine Partition. Unterstützt werden sie dabei meist durch einen Logical-Volume-Manager (LVM), der physische Partitionen zu logischen zusammenfasst. Als Nebenprodukt kann ein LVM auch Funktionalitäten wie RAID, Kompression oder Verschlüsselung bereitstellen. Der Volume-Manager von ZFS kennt derzeit vier RAID-Typen:
- ZFS-Mirror: Eine gerade Anzahl von Festplatten wird zu einem Spiegel zusammengefasst. Die Speicherkapazität entspricht der Hälfte der Gesamtkapazität aller Festplatten.
- ZFS-RAIDZ1: Dieser RAID-Typ entspricht einem RAID5. Mindestens drei Festplatten bilden hier ein Laufwerk. Die Daten und Prüfsummen werden auf alle drei Platten verteilt. Es darf maximal ein Fehlerfall eintreten, ohne dass es zu einem Totalausfall kommt.
- ZFS-RAIDZ2: Hierbei handelt es sich um ein RAID6. Es müssen mindestens vier Festplatten vorhanden sein, um einen solchen Pool anzulegen. Daten und Prüfsummen werden ebenfalls auf alle Platten verteilt. Allerdings dürfen bei diesem Typ zwei Fehlerfälle auftreten.
- ZFS-RAIDZ3: Dieser Typ ist eine Weiterentwicklung von ZFS-RAIDZ2. Hier dürfen drei Fehlerfälle auftreten, ohne dass es zum totalen Datenverlust kommt.
ZFS fasst diese Funktionen zusammen und bildet aus den physischen Datenträgern zunächst eine logische Einheit. Diese wird im ZFS-Sprachgebrauch Storage Pool genannt. Innerhalb eines Pools lassen sich dann beliebig viele logische Partitionen (mit je einem Dateisystem) – auch Datasets genannt – anlegen.
Dies erinnert alles stark an Hardware-RAID-Controller. Im Unterschied dazu können bei ZFS die logischen Partitionen dynamisch wachsen und schrumpfen, soweit die Größe des Pools es zulässt. Interessant ist dabei, dass jeweils die volle Bandbreite zur Verfügung steht. Weiterhin stellt dieser Pool eine Abstraktionsebene für Funktionen zum Belegen (malloc) und Freigeben (free) von Speicherbereichen auf Datenträgern bereit. In Abbildung 2 ist der Unterschied grafisch dargestellt.
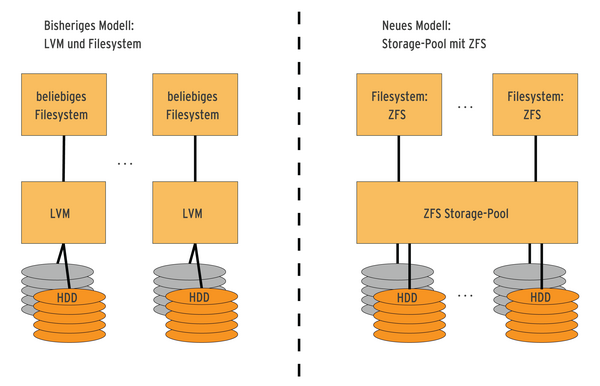 Abbildung 2: Unterschied zwischen LVM und Storage Pool.
Abbildung 2: Unterschied zwischen LVM und Storage Pool.
Im Gegensatz zu klassischen Dateisystemen wie Ext4, UFS2, FAT16 oder FAT32 ist ZFS ein so genanntes Transactional Filesystem. Das bedeutet, dass es sämtliche Dateioperationen durch Transaktionen absichert. Hierzu ein kurzer Ausflug in die Welt der Transaktionen: Sie werden meist im Bereich der relationalen Datenbanken eingesetzt, um Daten konsistent zu halten. Eine Transaktion ist eine logisch zusammengehörige Folge von einzelnen Operationen. Entweder alle Befehle der Transaktion werden ausgeführt und die entstandenen Änderungen werden übernommen (Commit) oder alle Änderungen werden rückgängig gemacht, als ob die Transaktion nie stattgefunden hätte (Rollback).
Dieses Modell wurde auch in ZFS realisiert. Traditionelle Dateisysteme schreiben Daten sofort an die zuvor durch Algorithmen ermitteltete Stelle auf den Datenträger (oder wenn sie die Cache-Daten auf die Festplatte schreiben). Wenn nun wegen eines Stromausfalls der Eintrag im Verzeichnisbaum nicht mehr geschrieben werden kann, liegt eine Inkonsistenz vor, die erst ein Dateisystem-Check wieder auflöst.
Ähnliche Artikel




Konfigurationsmanagement

Themen


